## Moving-head Disk Mechanism 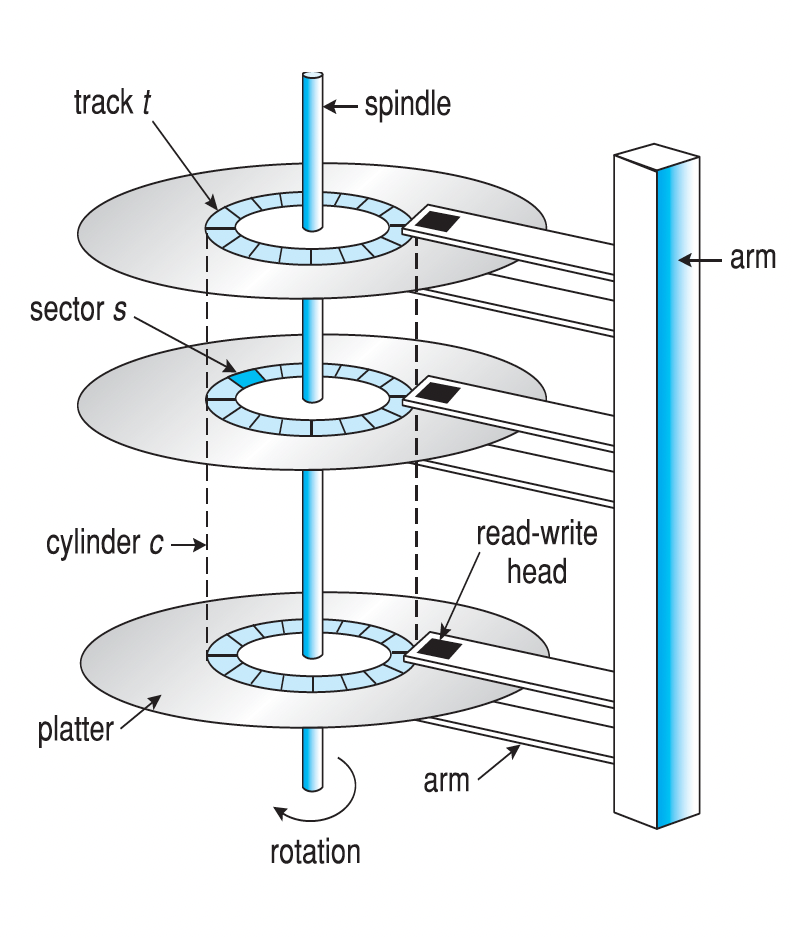 “移动头磁盘机制”是传统**硬盘驱动器(HDD)**的核心工作方式。它是一种用于在物理存储介质(即磁盘)上存储和检索数据的方法。这个机制的名称来自于其关键组成部分——一个可以在磁盘表面上移动的读写头。 以下是关于这个机制及其相关组件的详细介绍,基于提供的来源: 1. **基本组成和原理**: - HDD 包含一个或多个**盘片(platter)**,它们是扁平的圆形磁性表面,类似于 CD。 - 每个盘片的表面都有一个**读写头(read-write head)**,它“悬浮”在盘片表面上方。 - 这些读写头连接到一个**磁盘臂(disk arm)**上,磁盘臂作为一个单元移动所有的读写头。 - 盘片被分成逻辑上的**圆形磁道(circular tracks)**,磁道又进一步细分为**扇区(sectors)**。扇区是最小的传输单元。 - 在给定磁盘臂位置上所有盘片上的磁道集合构成一个**柱面(cylinder)**。一个驱动器中可能有数千个同心柱面。 - 数据以磁性方式记录在盘片上,并通过检测磁模式来读取。 - 驱动器马达使盘片高速旋转(RPM)[43, 69a]。 2. **数据组织和访问**: - 存储设备被抽象为大型的一维**逻辑块(logical block)**数组,逻辑块是最小的传输单元。 - 每个逻辑块映射到一个物理扇区或半导体页面。 - 在 HDD 上,逻辑块数组被映射到设备的扇区上。例如,逻辑块 0 可以是第一个盘片上最外层柱面的第一个磁道的第一个扇区。映射顺序通常是沿着磁道顺序进行,然后是柱面内其他磁道,再然后是从最外层到最内层的其他柱面。 - **逻辑块地址(LBA)**比扇区、柱面、头部的元组更容易用于算法。 - HDD 支持**原地重写(rewritten in place)**,并且可以直接访问它所包含的任何块。 - 磁盘 I/O 是以块为单位在内存和海量存储之间执行的。 ### 一、扇区(Sector)与块(Block):物理与逻辑的“最小单元绑定” 磁盘的 **物理层** 被划分为多个「扇区(Sector)」——这是磁盘硬件能直接寻址的最小存储单元(比如传统硬盘一个扇区固定为 512 字节,现代也有 4KB 等)。 操作系统为了**统一管理磁盘 I/O**,将 **逻辑层的访问单元** 定义为「块(Block)」,并让 **“一个扇区 = 一个块”**(即块大小由扇区的物理尺寸决定)。 💡 类比:把磁盘想象成「带格子的仓库」—— - 扇区 = 仓库里固定大小的「物理格子」(硬件层面的最小存储单位); - 块 = 操作系统规定的「逻辑搬运单元」(软件层面每次读写必须整“格”操作,且格子大小和物理扇区一致)。 ### 二、块大小:硬件“先天决定”,系统“后天统一” **磁盘系统的块大小(通常 512 字节,现代也有 4KB 等)由扇区的物理尺寸“先天”决定**。 **Disk systems** typically have a well-defined block size (*i.e.* 512KB) determined by the size of a sector 这种“统一块大小”的设计,让操作系统能以**标准化方式**管理磁盘 I/O(比如读/写操作必须按“块”为单位,不能拆分扇区单独操作)。 ### 三、磁盘的 I/O 特性:原地重写 + 随机访问 磁盘支持两项关键能力,使其区别于磁带等顺序存储设备: - 🖊️ **原地重写(In-place Rewrite)**:可以直接修改某个块的内容(比如把块 20 的内容从“ABC”改成“ABD”,无需先删除再重建整个块)。 - 🔀 **随机访问(Random Access)**:能直接跳转到任意块(比如要访问块 35,磁盘头可“瞬移”到对应位置,不像磁带必须从开头顺序卷到目标位置)。 💡 对比类比(理解“随机访问”的优势): - 磁带 → 图书馆里的“卷轴书”:想找第 100 页,必须从第 1 页卷到第 100 页(**顺序访问**); - 磁盘 → 图书馆里的“活页书”:想找第 100 页,直接翻到对应页码(**随机访问**)。 ### 四、磁盘 I/O 的“块级操作”:以块为单位,按编号访问 操作系统对磁盘的所有 I/O 操作,**必须以“块”为基本单位**,且块在磁盘中是 **“线性编号”** 组织的(比如块 0、块 1、块 2… 像数组一样排成一列)。 **All disk I/O is performed in units of one block (physical record) of the same size, indexed by block no. in a linear array** 举个例子:如果 I/O 请求序列是 `20, 35, 11`,磁盘会依次定位到**块 20 → 块 35 → 块 11**,分别执行读/写操作(类似“按索引找数组元素”)。 ### 五、逻辑记录 vs 物理块:“大小不匹配”的解决——**打包存储** It is unlikely that the physical record size will exactly match the length of the desired logical record. 现实中,应用程序的 **“逻辑记录(Logical Record)”**(比如一条用户信息、一笔订单数据)和磁盘的 **“物理块”** 往往大小不匹配: - 逻辑记录可能比块小(比如块 512 字节,逻辑记录仅 100 字节); - 逻辑记录长度甚至**不固定**(比如日志条目长度随内容变化)。 为解决这种“大小错位”,**“将多个逻辑记录打包到一个物理块”** 是常用方案。例如:把 5 个 100 字节的逻辑记录塞进 512 字节的块(5×100=500,剩余 12 字节可填充或忽略),以此提高存储效率。 💡 类比:物理块是「快递纸箱(固定大小)」,逻辑记录是「要寄的小物件(大小不一)」——把多个小物件塞一个纸箱,既省空间又方便搬运。 ### 总结:磁盘 I/O 的“标准化”与“灵活性”平衡 移动头磁盘机制的核心,是通过 **“块(=扇区)”** 实现**硬件与系统的标准化对接**,同时靠 **“随机访问、原地重写、逻辑记录打包”** 解决实际应用中**“多变数据格式”与“固定块大小”** 的适配问题。这种设计让磁盘既满足“高效批量读写”,又能灵活应对应用层的存储需求~ 通过「仓库格子类比」「磁带 vs 磁盘对比」「快递打包例子」,能把“扇区-块绑定”“I/O 特性”“逻辑与物理适配”这些抽象技术点讲得更通俗~ 📀 ## Layered File System - File system organized into layers - Each layer in the design uses the features of lower layers to create new features 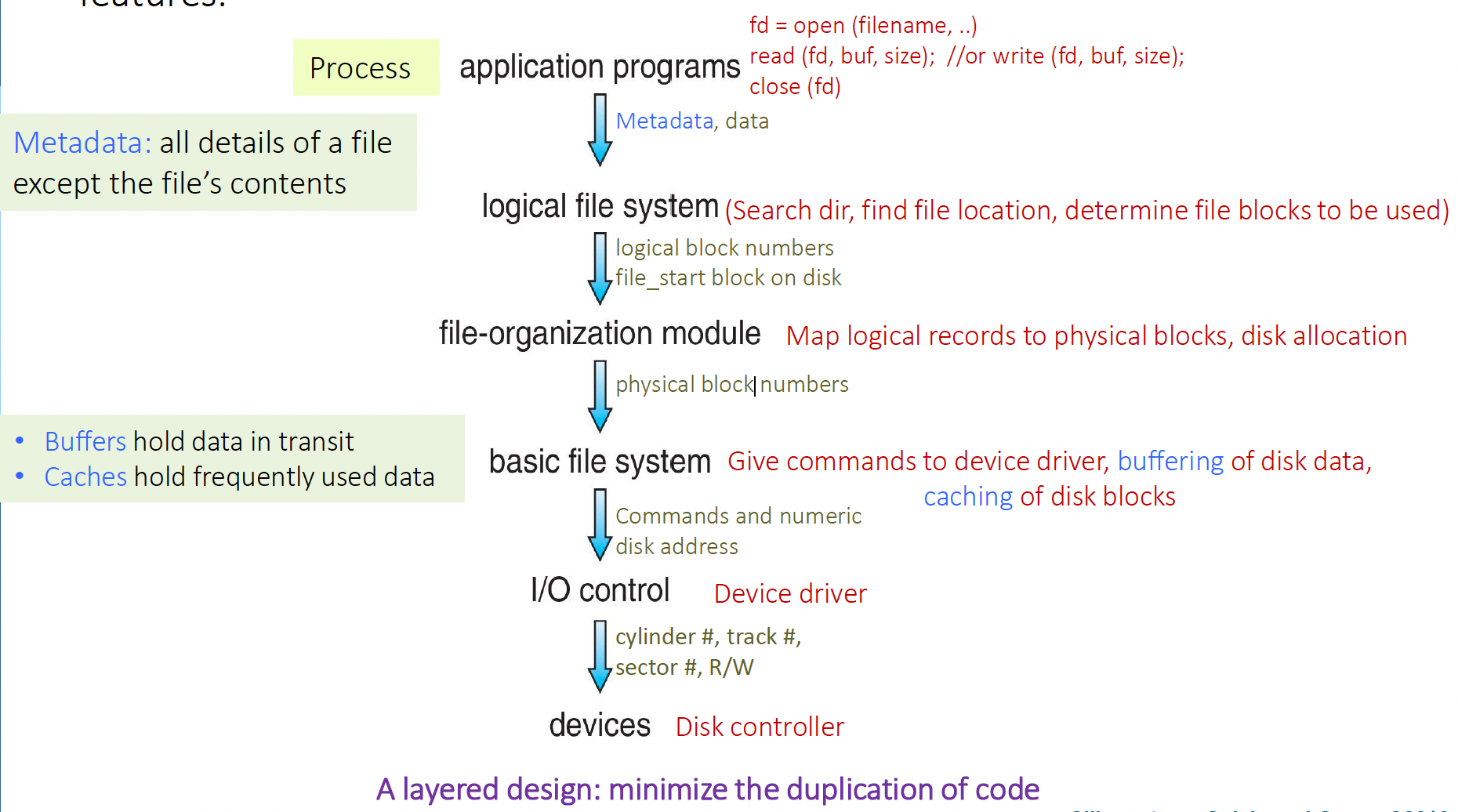 ## OS and File System - **One OS can support $\geq 1$ file systems** - **Many OS allow administrators or users to add file systems** - Each file system has its own format - disk file-system format - CD-ROM and DVD file-system formats - Unix supports: UFS (Unix File System), which is based on Fast File Systems - Linux supports over than 130 file systems - Extended File System (Standard Linux File System) - ext2, ext3, ext4 - Windows supports - Disk file formats - 16-bit File Allocation Table (FAT) - 32-bit File Allocation Table (FAT32) - New Technology File System (NTFS) - CD, DVD Blue-ray File System Formats ## File-System Implementation ### Requirements Structures used in file system implementation - Two categories of structures - **On-disk (on-storage) structures** contain information about - how to boot an OS stored in disk - the total number of blocks - the number and location of free blocks - the directory structure and individual files - **In-memory structures ** contain information used for - file-system management - Performance improvement via caching ### On-disk (on-storage) structures  要讲解 **磁盘存储结构(On-disk Structures)**,我们可以从「卷的物理布局」「核心数据结构」「不同文件系统的实现差异」三个维度展开,结合操作系统实例(如 Unix/Linux 的 UFS、Windows 的 NTFS)对比分析: #### 一、卷(Volume)的物理布局:从引导到数据的“四层结构” 一个磁盘卷(逻辑磁盘或分区)在物理上被划分为四个核心区域,如幻灯片底部示意图所示: ``` [引导块 (Boot Block)] → [超级块/卷控制块 (Superblock)] → [目录与文件控制块 (Directory & FCBs)] → [文件数据块 (File Data Blocks)] ``` ##### 1. 引导块(Boot Block) - **位置**:卷的**第一个块**(固定位置)。 - **作用**: - 存储**引导程序(Bootloader)**,用于启动操作系统(如 Windows 的 NTLDR、Linux 的 GRUB)。 - 若卷不包含操作系统,引导块为空或保留。 - **不同系统术语**: - Unix/Linux(UFS):称为 **引导块(Boot Block)**; - Windows(NTFS):称为 **分区引导扇区(Partition Boot Sector)**。 ##### 2. 超级块/卷控制块(Superblock/Volume Control Block) - **位置**:紧接引导块之后。 - **作用**:存储**卷的全局元数据**,是文件系统的“户口本”: - 卷的总块数、块大小(如 4KB); - 空闲块数量及指针(记录哪些块未被使用,用于分配新文件); - 空闲文件控制块(FCB)数量及指针(记录哪些 FCB 可用于创建新文件)。 - **不同系统术语**: - Unix/Linux(Ext 系列):称为 **超级块(Superblock)**; - Windows(NTFS):称为 **主文件表(Master File Table, MFT)**——本质是结构化的元数据数据库,而非简单块。 ##### 3. 目录与文件控制块(Directory & FCBs) - **位置**:超级块之后,存储文件系统的“索引”信息。 - **核心作用**: - **目录结构**:记录文件名与文件控制块的映射关系(如“`readme.txt` → inode 123”); - **文件控制块(FCB)**:每个文件对应一个 FCB,存储文件的元数据(权限、大小、创建时间、数据块位置等)。 - **不同系统实现**: - **Unix/Linux(UFS)**: - 目录项仅存储**文件名**和对应的 **inode 号**; - inode(索引节点)是独立的 FCB,包含文件元数据及数据块指针(如 12 个直接块、1 个间接块等)。 - **Windows(NTFS)**: - 所有目录项和 FCB 统一存储在 **主文件表(MFT)** 中,采用类似关系数据库的行记录结构; - MFT 不仅记录文件名、权限等,还直接存储小文件的内容(称为“常驻属性”)。 ##### 4. 文件数据块(File Data Blocks) - **位置**:卷的最后部分,存储文件的实际内容。 - **特点**: - 由 FCB 或 inode 中的“数据块指针”指向; - 大文件可能分散在多个不连续的数据块中(通过间接块或 MFT 指针链管理)。 #### 二、核心数据结构对比:Unix vs. Windows 的“元数据哲学” | **概念** | **Unix/Linux(UFS/Ext)** | **Windows(NTFS)** | | -------------- | ------------------------------------------------ | ------------------------------------------------- | | **卷控制块** | 超级块(Superblock):简单块结构,存储全局元数据 | 主文件表(MFT):结构化数据库,存储所有文件元数据 | | **文件元数据** | inode:独立于目录,通过 inode 号索引 | FCB:作为 MFT 的“行记录”,包含文件名和元数据 | | **目录项** | 仅存储文件名 + inode 号 | 存储文件名 + FCB 完整信息(MFT 中直接关联) | | **小文件优化** | 需访问 inode + 数据块 | MFT 直接存储小文件内容(减少磁盘寻道) | | **空闲块管理** | 超级块记录空闲块指针链 | MFT 中有专门记录空闲空间的“元文件”(如 $Bitmap) | **核心差异**: - Unix 采用**“分离式设计”**(目录存文件名,inode 存元数据),结构简洁,适合传统磁盘寻道优化; - NTFS 采用**“集成式数据库”**(MFT 统一管理所有信息),支持复杂元数据(如权限、加密、事务日志),适合现代高性能与可靠性需求。 #### 三、关键术语解析:从“为什么需要这些结构”理解设计逻辑 ##### 1. 为什么需要超级块/MFT? - **全局视角管理卷**:快速获取卷的总空间、空闲空间等信息,避免每次操作都遍历全卷; - **故障恢复基础**:记录空闲块状态,确保文件创建/删除时的元数据一致性(如 Ext4 的日志机制依赖超级块)。 ##### 2. 为什么目录不直接存文件数据? - **解耦合设计**:文件名可修改(如重命名),但文件元数据(如权限、数据块位置)不变,分离存储避免重复修改; - **高效查找**:目录仅需存储“短文件名+索引”,而非完整元数据,减少目录遍历开销(如 Unix 的 `ls` 命令快速列出文件名)。 ##### 3. 为什么 NTFS 的 MFT 能存小文件内容? - **减少 I/O 次数**:小文件(如几百字节)无需额外读取数据块,直接从 MFT 中读取,提升性能(如系统文件 `boot.ini` 通常直接存储在 MFT 中)。 #### 四、典型场景示例:文件创建的“幕后流程” 以在 Unix 系统创建文件 `test.txt` 为例,磁盘结构如何协作: 1. **引导块**:无操作(非引导卷); 2. **超级块**:查找空闲 inode 指针,分配一个空闲 inode(如 inode 500),更新空闲 inode 计数; 3. **目录结构**:在目标目录(如 `/home/user`)中添加一条记录 `test.txt → inode 500`; 4. **inode(FCB)**:在 inode 500 中记录文件权限(如 rw-r--r--)、大小(0 字节)、创建时间,数据块指针为空; 5. **数据块**:无操作(文件为空)。 **NTFS 流程类似但更集成**:在 MFT 中新增一行记录,直接包含文件名、权限、空数据(若文件小)或数据块指针(若文件大)。 #### 总结:磁盘结构的“管理金字塔” 从引导块(系统启动)→ 超级块/MFT(全局管理)→ 目录与 FCB(文件索引)→ 数据块(内容存储),磁盘结构形成了“从宏观到微观”的管理链条: - **底层硬件适配**:通过引导块实现系统启动,超级块/MFT 适配磁盘物理特性(块大小、寻道优化); - **上层功能支撑**:目录与 FCB 实现文件的“命名-寻址-权限”管理,数据块提供实际存储。 理解这些结构,就能明白操作系统如何在“0/1 物理磁盘”上构建出人类可理解的“文件与目录”世界~ 📊💾 ### In-Memory Structure 要讲解 **内存结构(In-Memory Structures)**,我们可以从「挂载管理」「目录加速」「文件打开状态的全局与进程级跟踪」三个维度拆解,结合**类比+场景示例**理解内存中如何高效管理文件系统运行时数据: #### 一、挂载表(Mount Table):记录“文件系统的内存地图” **包含:File-system mounts, mount points, file-system types** **核心作用** - 存储**当前系统中所有已挂载的文件系统信息**,相当于“挂载状态的实时台账”。 - 包含三大关键信息: 1. **挂载点(Mount Point)**:如 `/mnt/usb`(文件系统接入目录树的位置); 2. **文件系统类型 **:如 `ext4`、`NTFS`、`FAT32`(用于系统识别操作指令); 3. **设备标识**:如磁盘分区 `/dev/sdb1`、ISO 镜像路径(指向物理存储位置)。 类比场景 想象你有多个外接硬盘插在电脑上,挂载表就像**“外接设备管理器”**:记录每个硬盘插在哪个USB接口(挂载点)、硬盘的格式(文件系统类型)、硬盘的物理编号(设备标识)。系统需要访问文件时,先查挂载表找到对应的“位置地图”。 #### 二、目录结构缓存(Directory Structure Cache):加速“最近访问的目录查询” **Holds the directory information of recetly accessed directories** 核心作用 - 缓存**近期被访问过的目录元数据**(如目录下的文件名、子目录结构),避免频繁访问磁盘,提升文件检索速度。 - 典型场景: - 用户执行 `ls /usr/local` 后,该目录的结构会被存入缓存; - 后续再次访问 `/usr/local` 时,直接从内存读取目录内容,无需读取磁盘。 技术细节 - **缓存内容**:文件名与 inode/FCB 编号的映射关系(如 `bin → inode 1234`)、目录修改时间(用于缓存失效判断)。 - **淘汰策略**:采用 LRU(最近最少使用)算法,移除长时间未访问的目录条目,释放内存空间。 类比场景 类似**浏览器的网页缓存**:你第一次访问某个网页时,浏览器会下载完整内容并缓存;再次访问时,直接从缓存加载,速度更快。目录缓存就是操作系统的“文件路径浏览器缓存”。 #### 三、系统范围打开文件表(System Wide Open File Table):全局的“文件打开状态总账” 核心作用 - **面向所有进程**,记录**系统中所有已打开的文件信息**,是操作系统管理文件资源的“全局视角”。 - **For all processes, it contains a copy of the FCB of each file, tracking all open files and keeping the coutner of processes that have opened each file.** - 关键字段: 1. **FCB 副本**:存储文件元数据(如权限、大小、磁盘位置、创建时间),与磁盘上的 FCB/inode 同步; 2. **打开计数(引用计数)**:记录有多少个进程正在打开该文件(如计数为 3 表示 3 个进程打开了同一文件); 3. **文件状态**:是否只读、是否被锁定(用于并发访问控制)。 典型场景:多进程共享文件 假设进程 A 和进程 B 同时打开文件 `/etc/passwd`: 1. 系统表中创建一条记录,FCB 副本指向该文件的磁盘元数据,打开计数初始化为 1(进程 A 打开); 2. 进程 B 打开同一文件时,系统表找到已有记录,打开计数增至 2,无需重复读取磁盘元数据。 类比场景 类似**图书馆的“书籍借阅总台账”**: - 每本书(文件)对应一个条目,记录当前借阅人数(打开计数)、书籍位置(磁盘路径)、书籍状态(是否可外借/已损坏=文件权限); - 无论多少人借阅同一本书,总台账只记录一次书籍信息,避免重复登记。 #### 四、进程级打开文件表(Per Process Open File Table):进程的“私有文件访问记录” 核心作用 - **每个进程独立维护**,记录该进程当前打开的所有文件,是进程视角的“文件访问上下文”。 - 关键字段: 1. **指向系统表的指针**:关联到系统范围打开文件表中的对应条目(共享 FCB 元数据); 2. **文件读写指针**:记录该进程对文件的最后操作位置(如读取到第 100 字节,下次从 101 开始); 3. **访问权限**:进程对文件的权限(如只读、读写,可能因进程不同而不同)。 典型场景:同文件不同进程的独立操作 进程 A 和进程 B 同时读取文件 `data.txt`: - 系统表中共享 FCB(文件大小、磁盘位置等); - 进程 A 的读写指针在第 50 字节(刚读完前半部分),进程 B 的读写指针在第 0 字节(刚打开); - 两进程各自的操作互不干扰,系统通过进程表独立跟踪位置。 类比场景 类似**图书馆中多个读者的“个人借阅记录”**: - 总台账(系统表)记录书籍的全局信息(如编号、位置); - 每个读者的借阅卡(进程表)记录自己借的书、当前阅读进度(读写指针)、借阅权限(如是否可续借=访问权限)。 #### 五、四者协同工作:从“文件打开”到“读写操作”的流程 以进程打开文件 `/home/user/doc.txt` 为例,内存结构如何协作: 1. **挂载表查询**:确认 `/home` 所在的文件系统已挂载(如挂载点 `/home`,类型 `ext4`,设备 `/dev/sda5`); 2. **目录缓存查找**:检查 `/home/user` 目录是否在缓存中,若在则直接获取 `doc.txt` 的 inode 号,否则从磁盘读取并更新缓存; 3. **系统打开文件表操作**: - 若文件未打开,创建新条目:FCB 副本读取磁盘 inode,打开计数设为 1; - 若文件已打开,找到现有条目,打开计数+1; 4. **进程打开文件表操作**:创建条目,指向系统表中的对应条目,初始化读写指针为 0,记录进程权限(如用户 `user` 有读写权限); 5. **读写操作**:进程根据读写指针定位数据,系统表维护全局打开状态,目录缓存加速后续目录访问。 #### 总结:内存结构的“效率与隔离”设计目标 | 结构名称 | 核心目标 | 典型数据 | 跨进程共享性 | | -------------- | -------------------------- | --------------------------- | ------------ | | 挂载表 | 管理文件系统挂载状态 | 挂载点、文件系统类型 | 全局共享 | | 目录结构缓存 | 加速目录查询 | 文件名→inode 映射、修改时间 | 全局共享 | | 系统打开文件表 | 跟踪全局文件打开状态 | FCB 副本、打开计数 | 全局共享 | | 进程打开文件表 | 维护进程私有文件访问上下文 | 读写指针、访问权限 | 进程私有 | 通过这四层结构,操作系统实现了: - **效率优化**:缓存减少磁盘 I/O,共享表避免重复元数据存储; - **安全隔离**:进程级表确保各进程操作独立(如读写位置、权限隔离); - **资源管理**:全局表跟踪文件打开计数,避免文件被误删(需所有进程关闭后才允许删除)。 理解这些内存结构,就能明白操作系统如何在内存中“动态编织”文件系统的运行时状态~ 📚💻 ## File Open and Close ### Open File 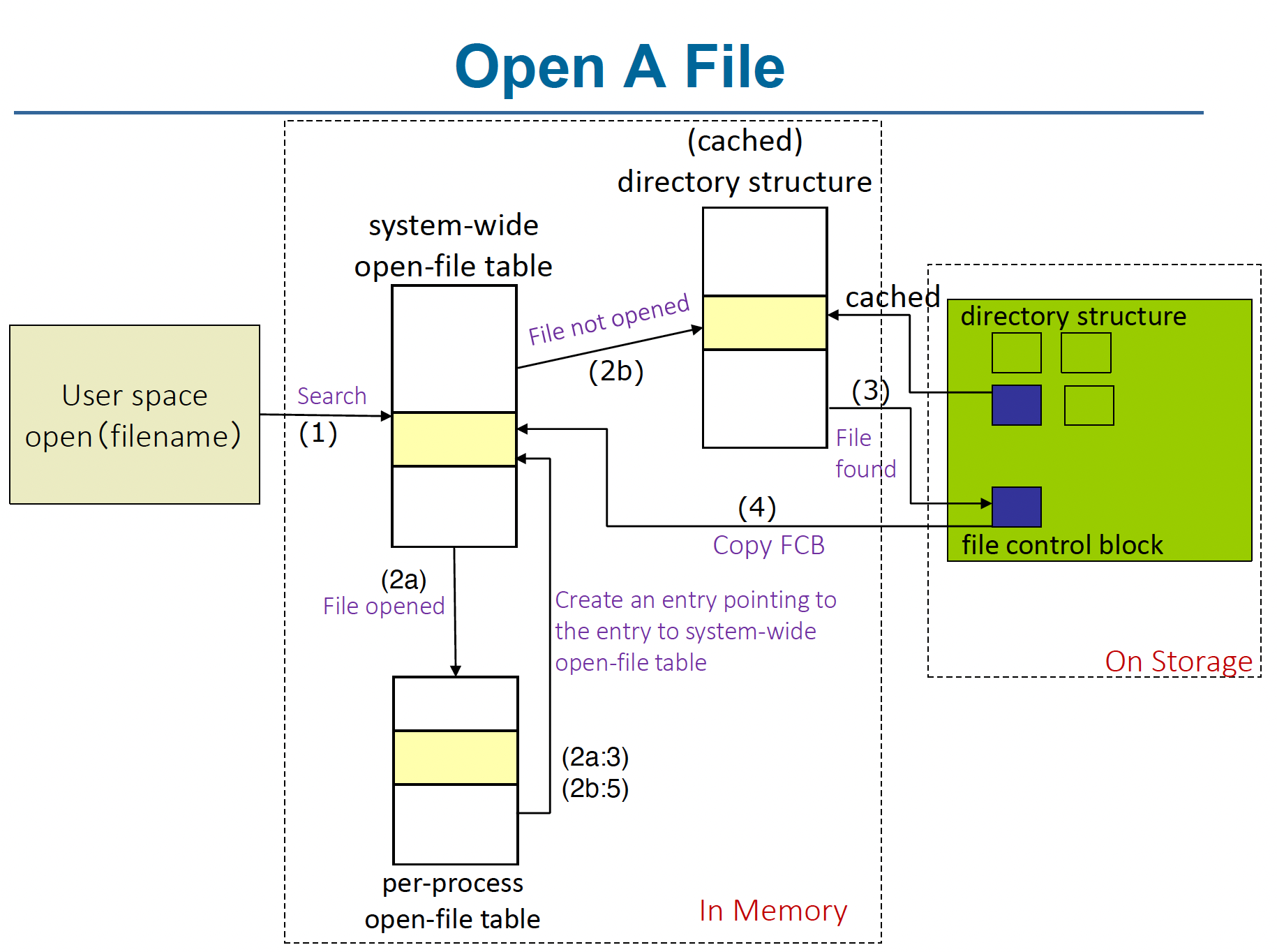 - Search the **directory structure** on disk for the file and copy the content of entry(**metadata**)to **system-wide open file table** if the file is opened for the first time - Update the per-process open-file table by adding a pointer to system-wide open file table ### Close a file - Remove the file entry in system-wide open file table if no process to use it anymore - Update the per-process table by removing a pointer to system-wide open file table ## Virtual File Systems 一句话说人话,VFS = Java - VFS allows the same API to be used for different types of file systems - Separatesfile-system generic operations fromimplementation details - Implementation can be one of many file systems types, or network file system ## Directory Implementation - Linear list of file names with pointer to the data blocks - 说人话,搞个数组存 file name. - Hash Table - Linear list with hash data structure - 说人话,把线性表变成哈希当作 map 用 ## Allocation Methods ### Contiguous allocation - Each file occupies set of contiguous blocks - Each file can be located by start block # and length (total number of blocks) - *i.e.* A file that occupies $n$ blocks: $b, b+1, \cdots , b + n - 1$ - Advantage - Simple - Each to access - Minimal disk head movement - 磁盘按磁道(Track)和扇区(Sector)组织,连续块通常位于同一磁道或相邻磁道,**磁头移动距离最短**。 - Problems - Not suitable for a file with varied size: file size must be determined at the begenning (size-declaration) - 若预留空间过大,浪费磁盘;预留过小,文件无法写入。 - External Framgentation - 现象:随着文件频繁创建和删除,磁盘空闲块被分割为不连续的小块,导致: - 总空闲空间足够,但无法分配大文件(如空闲块总和为 100GB,但都是 <1GB 的碎片)。 - Solution: compacts all free space into one contiguous space - Compaction can be done off-line (down time) or on-line - Internal Fragmentation #### Example of Contiguous Allocation ##### 前提条件 - **逻辑地址(LA, Logical Address)**:文件内的字节偏移,从 `0` 开始计数。 - **块大小**:`512 字节`(每个磁盘块存储 512 字节数据)。 - **文件 `tr` 的元数据**: - 起始物理块号:`14`(即该文件存储在磁盘的第 14、15、16 块,共 3 个连续块)。 - 逻辑地址到物理地址的转换公式: $$ \text{物理地址} = (\text{Q} + \text{起始块号}) \times \text{块大小} + \text{R} $$ 其中: - **Q**:逻辑地址对应的**相对块号**(相对于文件起始块的偏移,从 0 开始)。 - **R**:逻辑地址在块内的**字节偏移量**($0 \leq R < 512$)。 问题:For tile tr, if a byte's LA is 1025, what is its physical address? **Step 1: 拆分逻辑地址为块号和偏移量** $$ \text{逻辑地址} \div \text{块大小} = \text{商(Q)} \quad \text{余(R)} $$ 代入: $$ 1025 \div 512 = 2 \quad \text{余} \quad 1 $$ - **Q = 2**:表示逻辑地址 `1025` 位于文件内的第 **3 个块**(相对块号从 0 开始,Q=0 是第 1 块,Q=1 是第 2 块,Q=2 是第 3 块)。 - **R = 1**:表示在块内的偏移量为 `1 字节`(即该地址是块内的第 2 个字节,因为偏移从 0 开始)。 **Step 2: 计算物理块号** 文件 `tr` 的起始物理块号为 `14`,相对块号 `Q=2` 对应的物理块号为: $$ \text{物理块号} = \text{起始块号} + \text{Q} = 14 + 2 = 16 $$ 即该逻辑地址对应磁盘的 **第 16 块**。 **Step 3: 计算物理地址** $$ \text{物理地址} = \text{物理块号} \times \text{块大小} + \text{R} = 16 \times 512 + 1 = 8192 + 1 = 8193 $$ **常见错误** 1. **相对块号 Q 从 0 开始**: - 不要误认为 Q 是“第几个块”(如 Q=2 是第 3 个块),而是相对于起始块的偏移量(起始块对应 Q=0)。 2. **块大小的作用**: - 块大小决定了逻辑地址拆分的粒度。若块大小为 4KB(4096 字节),则逻辑地址除以 4096 得到 Q 和 R。 3. **连续分配的地址唯一性**: - 由于文件存储连续,物理块号可通过“起始块 + Q”直接计算,无需查找链表或索引表,这是连续分配**访问高效**的核心原因。 #### Modified Contiguous Allocation  ### Linked Allocation - Each file is a linked list of blocks, ends at `NULL` pointer - Each block contains pointer to next block - Advantages - Solved the external-fragmentation problem and size-declaration problems of contiguous allocation - No need to find contiguous blocks - Disadvantage - Slow, you have to visit $O(n)$ elements #### Example 1 - Each file is a linked list of blocks, ends at `NULL` pointer - Blocks may be scattered anywhere on the disk - Physical address - $R$ byte in the $Q$ block in the list (index starts from $0$) - $Q$ block index in the list relative to the start - $R$ displacement into the block  **Step 1: 得到 data 部分的大小** $$ \text{data} = \text{block size} - \text{pointer} = 512 - 1 = 511 \text{ bytes} $$ - 逻辑地址需按**数据部分的大小**拆分,而非整个块的大小。 **Step 2: 逻辑地址拆分** $$ \text{逻辑地址} \div \text{数据部分大小} = \text{商(Q)} \quad \text{余(R)} $$ - **Q**:链表中的**块索引**(从 0 开始),表示逻辑地址属于第 $Q+1$ 个块。 - **R**:块内数据部分的**字节偏移**($0 \leq R < 511$)。 #### Example 2 ##### Linked allocation 的关键差别 | | 顺序 (contiguous) allocation | **链式 (linked) allocation** | | ----------------- | ---------------------------- | --------------------------------- | | 磁盘块在物理空间 | 必须相邻 | 可以散落在任何位置 | | 块号计算 | `start + Q` | **只能沿着指针逐块走** | | 访问第 *Q* 块耗时 | O(1) | O(Q)(最坏要走完前面 *Q* 个指针) | 在链式分配里,每个磁盘块的“下一块”信息就藏在指针字节里。文件的块可以像你的例子那样: ``` 9 → 16 → 1 → 10 → 25 ``` 完全不连续。 于是: - **逻辑地址 512** 告诉我们“落在第 1 块(从 0 数)”,但 - 第 1 块的 **物理块号** 并不是 `start (9) + 1 = 10`,而是链表里指针跳过去的 **16**。 如果你硬套 `(9 + Q)`: | Q | `(9 + Q)` 得到的“假块号” | 真实链表块号 | | ---- | ------------------------ | ------------ | | 0 | 9 | 9 | | 1 | 10 | **16** ⟵ 错 | | 2 | 11 | 1 ⟵ 再错 | 可见只要链表里出现一次“跨越”,这条简单算式就失效了。 ##### 关于块大小与块内偏移 - **块大小 (block_size)** 依旧是 512 Bytes——这是磁盘对块寻址的粒度。 - 指针 1 Byte 只是占用了块最后 1 Byte 的**存储空间**,它不会改变“物理块大小”。 因此块内有效数据区只有 511 Bytes,但物理块地址仍按 512 Bytes 对齐。 **所以我们的步骤是:** 1. **`Q = ⌊Logical / 511⌋`,`R = Logical mod 511`** 2. **沿链表走 Q 步 找到真正的物理块号** 3. **物理地址二元组 = (物理块号, R)** **在你的例子里得到 (16, 1)。这就是为什么不能直接用 `(Q + 起始块号)` 来推算物理块号。** ### Linked Allocation Variation: File Allocation Table - An important variation on linked allocation used in MS-DOS - Indexed in physical block no. - Each entry stores the no. of next block for this file - Like a linked list, but faster on disk and cacheable - Simple and efficient #### **1. 什么是FAT?** **文件分配表(File Allocation Table, FAT)** 是微软DOS系统中使用的一种磁盘空间分配方法,属于**链式分配的改进版本**。它通过一个集中的表格记录文件块的链接关系,而非在每个数据块中存储指针,从而提升了访问效率和空间利用率。 #### **2. FAT的核心特点** ##### (1)**基于物理块号的索引** - **索引方式**:FAT表以**物理块号**为索引(下标),每个条目对应一个物理块的“下一块地址”。 - 例如:物理块号为217的条目,记录该块的下一个块号(如618)。 - **表格结构**:FAT表存储在磁盘固定位置(如引导扇区),开机时加载到内存,支持快速查询。 ##### (2)**集中存储块链接关系** - **传统链式分配**:每个数据块末尾需存储下一块的指针(如1字节),占用用户数据空间。 - **FAT模式**:**数据块中无需存储指针**,所有块的链接关系集中存储在FAT表中。 - 优势:每个数据块的全部空间(如512字节)均可用于存储用户数据,无额外开销。 ##### (3)**快速访问与缓存友好** - **无需磁盘寻道遍历**:传统链式分配需逐个块读取指针(多次磁盘I/O),而FAT表在内存中可直接查询,访问速度大幅提升。 - **缓存特性**:FAT表常驻内存(或缓存),后续访问无需重复读取磁盘,适合频繁访问的文件系统。 ##### (4)**简单高效的链式逻辑** - 本质上仍是链式结构(块间逻辑上串联),但通过集中式表格实现了**顺序访问高效性**与**元数据管理便捷性**的平衡。 #### **3. FAT的工作原理(示例解析)** 以幻灯片中的文件`test`为例: - **目录项**:记录文件的**起始块号217**。 - **FAT表结构**: | 物理块号 | FAT表条目(下一块号) | | -------- | ---------------------------------- | | 217 | 618(指向第二个块) | | 618 | 339(指向第三个块) | | 339 | -1(或特定结束标记,表示文件结束) | - **文件块链**:`217 → 618 → 339` - **访问流程**: 1. 从目录项获取起始块号217。 2. 查FAT表中217的条目,得到下一块618。 3. 查FAT表中618的条目,得到下一块339。 4. 查FAT表中339的条目,发现结束标记,遍历完成。 #### **4. FAT vs. 传统链式分配:核心区别** | **特性** | **传统链式分配** | **FAT(链式分配变体)** | | ---------------- | ------------------------------- | ------------------------------- | | **指针存储位置** | 每个数据块末尾(占用用户空间) | 集中存储在FAT表(不占用数据块) | | **访问效率** | 需逐块读取指针(多次磁盘I/O) | 内存中直接查询FAT表(快速) | | **随机访问支持** | 仅能顺序访问 | 可通过FAT表跳转(需遍历链条) | | **空间利用率** | 每个块需预留指针空间(如1字节) | 数据块全为用户数据,无开销 | | **元数据管理** | 分散在数据块中 | 集中在FAT表(易于维护和备份) | #### **5. FAT的优缺点** - **优点**: 1. **高效性**:内存中查询FAT表,减少磁盘I/O次数。 2. **空间利用率高**:数据块无指针开销。 3. **实现简单**:适合早期操作系统(如DOS)的硬件环境。 - **缺点**: 1. **FAT表占用内存**:磁盘容量越大,FAT表条目越多(如FAT32用32位表示块号)。 2. **随机访问受限**:仍需链式遍历,不适合大规模文件的随机读写(对比索引分配)。 #### **6. 为什么FAT比传统链式分配“更快”?** - **关键优化**: - **一次磁盘读取,多次内存查询**:FAT表只需首次加载到内存,后续访问直接查内存,无需每次访问块时读取指针(传统链式分配需每次读取块内指针,涉及磁盘寻道)。 - **缓存友好**:FAT表常驻内存或缓存,符合局部性原理,提升重复访问效率。 #### **总结:FAT的核心价值** FAT通过**集中式元数据管理**(FAT表)和**内存缓存技术**,在保持链式分配灵活性的同时,显著提升了访问速度和空间利用率。尽管其设计较简单,但在早期操作系统中(如DOS、早期Windows)被广泛采用,成为链式存储优化的经典案例。 ### Indexed Allocation #### **1. 什么是索引分配?** **索引分配**是一种将文件数据块的指针(物理地址)集中存储在**索引块(Index Block)**中的磁盘分配方法。每个文件拥有独立的索引块,其中每个条目对应一个数据块的物理地址。通过索引块,系统可以直接定位任意数据块,无需顺序遍历,从而支持高效的随机访问。 #### **2. 核心原理与结构** ##### (1)**索引块的作用** - **集中存储指针**:所有数据块的物理地址被存储在一个或多个索引块中,而非分散在数据块内部(如链式分配)。 - Bring all the pointers together into the index blocks - 例:若文件由3个数据块组成(块号12、45、78),其索引块包含3个条目,分别指向这3个块。 - **目录项关联索引块**:文件的目录项中仅存储**索引块的物理地址**,而非数据块地址。 - Each entry points to a block in a file - Each file has its own index block(s) of pointers to its data blocks ##### (2)**访问流程** 1. 从目录项获取索引块地址,读取索引块到内存。 2. 根据逻辑块号(如第n个数据块),直接查询索引块中第n个条目,获取对应数据块的物理地址。 3. 访问目标数据块。 **示例图示**: ``` 目录项: 文件名称: test 索引块地址: 999(假设索引块存于物理块999) 索引块(块999)内容: 条目1 → 数据块12 条目2 → 数据块45 条目3 → 数据块78 逻辑块号2 → 直接查索引块条目2,访问数据块45 ``` #### **3. 关键优势** ##### (1)**支持随机访问(Random Access)** - 无需像链式分配那样顺序遍历块链,可直接通过索引块定位任意数据块。 - **应用场景**:数据库文件、多媒体文件(需频繁跳转读取)。 ##### (2)**无外部碎片(No External Fragmentation)** - 数据块可离散分配在磁盘任意位置,只需索引块记录其地址。 - 解决了连续分配中“碎片导致空间无法利用”的问题(如连续分配需要大块连续空间,而索引分配允许零散空间被高效利用)。 ##### (3)**分配灵活** - 新增或删除数据块时,只需修改索引块条目,无需移动其他数据块(对比连续分配的“整块移动”)。 #### **4. 主要缺点** ##### (1)**索引块的空间开销** - **小文件效率低**:即使文件仅占1个数据块,仍需至少1个索引块,导致空间浪费。 - 例:块大小为4KB,指针占4字节,一个索引块可存储 $ \frac{4KB}{4B} = 1024 $ 个指针。若文件仅含1个数据块,索引块仍需4KB空间,总开销为8KB(数据块+索引块),利用率仅50%。 - **对比链式分配**:链式分配(如FAT)无需为每个文件单独分配索引块,全局FAT表共享空间,小文件开销更低。 ##### (2)**索引块可能成为性能瓶颈** - 访问大文件时,若索引块过大(需多个索引块),可能需要多次磁盘I/O读取索引块(可通过多级索引缓解,但增加复杂度)。 #### **5. 与链式分配(FAT)的对比** | **特性** | **索引分配** | **链式分配(FAT)** | | ------------ | ------------------------ | ----------------------------- | | **指针存储** | 每个文件独立索引块 | 全局FAT表 | | **访问方式** | 随机访问(直接查索引) | 顺序访问(遍历链条) | | **外部碎片** | 无 | 无(块可离散) | | **空间开销** | 索引块(小文件浪费显著) | FAT表(全局共享,小文件友好) | | **典型应用** | 大文件、随机访问场景 | 中小文件、顺序访问场景 | #### **6. 扩展:多级索引(Multi-Level Indexing)** - **问题**:当文件极大时,单级索引块可能无法容纳所有数据块指针(如块大小4KB,指针4字节,单索引块最多1024个指针,对应文件大小4MB)。 - **解决方案**: 1. **二级索引**:索引块中存储“次级索引块”的指针,次级索引块再存储数据块指针。 - 例:一级索引块指向1024个二级索引块,每个二级索引块指向1024个数据块,总数据块数为 $1024 \times 1024 = 1,048,576$,对应文件大小约4TB(4KB/块)。 2. **三级索引**:进一步扩展层级,支持更大文件(如EXT4文件系统的间接块机制)。 #### **7. 总结:索引分配的适用场景** - **优势场景**: - 需要频繁随机访问的大文件(如数据库、视频编辑文件)。 - 对空间碎片敏感的系统(如SSD,避免频繁擦除整块)。 - **劣势场景**: - 大量小文件(索引块开销占比过高)。 - 仅需顺序访问的场景(链式分配更高效)。 索引分配通过“空间换时间”的策略,在随机访问性能和碎片管理上优于传统分配方式,成为现代文件系统(如EXT2/3/4、NTFS)的核心技术之一。 #### Example ##### 索引分配示例解析 ###### **图示关键信息** - **文件jeep的索引块**:存储于物理块19。 - **索引块内容**(假设指针从索引0开始): | 索引位置 | 指针值(物理块号) | 含义 | | -------- | ------------------ | ------------------- | | 0 | 9 | 逻辑块0对应数据块9 | | 1 | 16 | 逻辑块1对应数据块16 | | 2 | 1 | 逻辑块2对应数据块1 | | 3 | 10 | 逻辑块3对应数据块10 | | 4 | 25 | 逻辑块4对应数据块25 | | 5~6 | -1(0xFF) | 空指针(无数据块) | - **假设条件**: - 指针大小:1字节(值范围:0~255,-1用0xFF表示)。 - 块大小:512字节。 ###### **问题1:LA = 513的物理地址计算** ##### 步骤1:解析逻辑地址(LA) $$ \text{逻辑块号} = \left\lfloor \frac{LA}{\text{块大小}} \right\rfloor = \left\lfloor \frac{513}{512} \right\rfloor = 1 $$ $$ \text{块内偏移量} = LA \mod \text{块大小} = 513 \mod 512 = 1 $$ ##### 步骤2:查询索引块获取物理块号 - 逻辑块号1对应索引块的**索引位置1**,指针值为**16**(即数据块16)。 ##### 步骤3:计算物理地址 - 物理块号16的起始地址:$16 \times 512 = 8192$ 字节。 - 块内偏移量1字节。 $$ \text{物理地址} = 16 \times 512 + 1 = 8193 $$ **答案1**:物理地址为 **8193**。 ###### **问题2:256KB文件需要的索引块数量** ##### 步骤1:计算数据块数量 $$ \text{文件大小} = 256\text{K} = 256 \times 1024 = 262144 \text{字节} $$ $$ \text{数据块数} = \frac{262144}{512} = 512 \text{个} $$ ##### 步骤2:计算单个索引块可容纳的指针数 $$ \text{单索引块指针数} = \frac{\text{块大小}}{\text{指针大小}} = \frac{512}{1} = 512 \text{个} $$ ##### 步骤3:判断索引块数量 - 512个数据块需要512个指针,恰好填满**1个索引块**(512指针/块)。 - 无需多级索引(单级索引足够)。 **答案2**:需要 **1个索引块**。 ##### **关键总结** 1. **索引分配的地址转换**: - 逻辑地址 → 逻辑块号 + 偏移量 → 索引块查询物理块号 → 物理地址 = 物理块起始地址 + 偏移量。 2. **索引块数量计算**: - 单级索引块数 = $\left\lceil \frac{\text{数据块数}}{\text{单块指针数}} \right\rceil$,本例中为1。 - 若数据块数超过单块指针数(如513个数据块),则需2个索引块。 ### Comparison | | Contiguous allocation | Linked allocation | Linked Allocation(FAT) | Indexed allocation | | -------------------------- | ------------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | | allocation | contiguous | scattered | scattered | scattered | | Directory hold information | For each file: file name, start block, number of blocks | For each file: file name, start block, end block. Linked through pointer | For each file: file name, start block<br>• One volume table indexed by block no. including next block no.<br> Linked through block no. | For each file: Index block no<br>• Index block: Pointers to data blocks | | Direct access support | Yes | No | Yes (Partial) | Yes | | fragmentation | External, internal | Internal | Internal | Internal | | Overhead | No | Pointer | FAT | Index block | | File size declaration | Necessary | Not necessary | Not necessary | Not necessary | ## Indexed Allocation – Schemes in Handling Large Files - One index block is not enough for large files - Three schemes to solve this issue - Linked scheme - Multilevel index - Combined scheme ## Free-Space Management - File system need to track available (free) blocks - Approaches - Bit vector (map) - Linked list - Groupiong - Counting ## Efficiency and Performance The efficient use of storage device space depends on: - Disk allocation method - **(Contiguous, Linked, and Indexed)** - Directory structure / algorithms - Types of data kept in file’s directory entry - Allocation of metadata structures - Fixed-size or varying-size data structures (e.g. the open file tables) **Ways to improve** efficiency and performance: - Keep data and metadata close together (for hard disk, but not SSD) - Use **buffer cache** for quick access - Use **asynchronous writes** (No need to write to disk immediately) - Use **Trim** mechanism (Keep the unused blocks for writing, No need to do garbage collection and erase steps before the device is nearly full) Loading... ## Moving-head Disk Mechanism  “移动头磁盘机制”是传统**硬盘驱动器(HDD)**的核心工作方式。它是一种用于在物理存储介质(即磁盘)上存储和检索数据的方法。这个机制的名称来自于其关键组成部分——一个可以在磁盘表面上移动的读写头。 以下是关于这个机制及其相关组件的详细介绍,基于提供的来源: 1. **基本组成和原理**: - HDD 包含一个或多个**盘片(platter)**,它们是扁平的圆形磁性表面,类似于 CD。 - 每个盘片的表面都有一个**读写头(read-write head)**,它“悬浮”在盘片表面上方。 - 这些读写头连接到一个**磁盘臂(disk arm)**上,磁盘臂作为一个单元移动所有的读写头。 - 盘片被分成逻辑上的**圆形磁道(circular tracks)**,磁道又进一步细分为**扇区(sectors)**。扇区是最小的传输单元。 - 在给定磁盘臂位置上所有盘片上的磁道集合构成一个**柱面(cylinder)**。一个驱动器中可能有数千个同心柱面。 - 数据以磁性方式记录在盘片上,并通过检测磁模式来读取。 - 驱动器马达使盘片高速旋转(RPM)[43, 69a]。 2. **数据组织和访问**: - 存储设备被抽象为大型的一维**逻辑块(logical block)**数组,逻辑块是最小的传输单元。 - 每个逻辑块映射到一个物理扇区或半导体页面。 - 在 HDD 上,逻辑块数组被映射到设备的扇区上。例如,逻辑块 0 可以是第一个盘片上最外层柱面的第一个磁道的第一个扇区。映射顺序通常是沿着磁道顺序进行,然后是柱面内其他磁道,再然后是从最外层到最内层的其他柱面。 - **逻辑块地址(LBA)**比扇区、柱面、头部的元组更容易用于算法。 - HDD 支持**原地重写(rewritten in place)**,并且可以直接访问它所包含的任何块。 - 磁盘 I/O 是以块为单位在内存和海量存储之间执行的。 ### 一、扇区(Sector)与块(Block):物理与逻辑的“最小单元绑定” 磁盘的 **物理层** 被划分为多个「扇区(Sector)」——这是磁盘硬件能直接寻址的最小存储单元(比如传统硬盘一个扇区固定为 512 字节,现代也有 4KB 等)。 操作系统为了**统一管理磁盘 I/O**,将 **逻辑层的访问单元** 定义为「块(Block)」,并让 **“一个扇区 = 一个块”**(即块大小由扇区的物理尺寸决定)。 💡 类比:把磁盘想象成「带格子的仓库」—— - 扇区 = 仓库里固定大小的「物理格子」(硬件层面的最小存储单位); - 块 = 操作系统规定的「逻辑搬运单元」(软件层面每次读写必须整“格”操作,且格子大小和物理扇区一致)。 ### 二、块大小:硬件“先天决定”,系统“后天统一” **磁盘系统的块大小(通常 512 字节,现代也有 4KB 等)由扇区的物理尺寸“先天”决定**。 **Disk systems** typically have a well-defined block size (*i.e.* 512KB) determined by the size of a sector 这种“统一块大小”的设计,让操作系统能以**标准化方式**管理磁盘 I/O(比如读/写操作必须按“块”为单位,不能拆分扇区单独操作)。 ### 三、磁盘的 I/O 特性:原地重写 + 随机访问 磁盘支持两项关键能力,使其区别于磁带等顺序存储设备: - 🖊️ **原地重写(In-place Rewrite)**:可以直接修改某个块的内容(比如把块 20 的内容从“ABC”改成“ABD”,无需先删除再重建整个块)。 - 🔀 **随机访问(Random Access)**:能直接跳转到任意块(比如要访问块 35,磁盘头可“瞬移”到对应位置,不像磁带必须从开头顺序卷到目标位置)。 💡 对比类比(理解“随机访问”的优势): - 磁带 → 图书馆里的“卷轴书”:想找第 100 页,必须从第 1 页卷到第 100 页(**顺序访问**); - 磁盘 → 图书馆里的“活页书”:想找第 100 页,直接翻到对应页码(**随机访问**)。 ### 四、磁盘 I/O 的“块级操作”:以块为单位,按编号访问 操作系统对磁盘的所有 I/O 操作,**必须以“块”为基本单位**,且块在磁盘中是 **“线性编号”** 组织的(比如块 0、块 1、块 2… 像数组一样排成一列)。 **All disk I/O is performed in units of one block (physical record) of the same size, indexed by block no. in a linear array** 举个例子:如果 I/O 请求序列是 `20, 35, 11`,磁盘会依次定位到**块 20 → 块 35 → 块 11**,分别执行读/写操作(类似“按索引找数组元素”)。 ### 五、逻辑记录 vs 物理块:“大小不匹配”的解决——**打包存储** It is unlikely that the physical record size will exactly match the length of the desired logical record. 现实中,应用程序的 **“逻辑记录(Logical Record)”**(比如一条用户信息、一笔订单数据)和磁盘的 **“物理块”** 往往大小不匹配: - 逻辑记录可能比块小(比如块 512 字节,逻辑记录仅 100 字节); - 逻辑记录长度甚至**不固定**(比如日志条目长度随内容变化)。 为解决这种“大小错位”,**“将多个逻辑记录打包到一个物理块”** 是常用方案。例如:把 5 个 100 字节的逻辑记录塞进 512 字节的块(5×100=500,剩余 12 字节可填充或忽略),以此提高存储效率。 💡 类比:物理块是「快递纸箱(固定大小)」,逻辑记录是「要寄的小物件(大小不一)」——把多个小物件塞一个纸箱,既省空间又方便搬运。 ### 总结:磁盘 I/O 的“标准化”与“灵活性”平衡 移动头磁盘机制的核心,是通过 **“块(=扇区)”** 实现**硬件与系统的标准化对接**,同时靠 **“随机访问、原地重写、逻辑记录打包”** 解决实际应用中**“多变数据格式”与“固定块大小”** 的适配问题。这种设计让磁盘既满足“高效批量读写”,又能灵活应对应用层的存储需求~ 通过「仓库格子类比」「磁带 vs 磁盘对比」「快递打包例子」,能把“扇区-块绑定”“I/O 特性”“逻辑与物理适配”这些抽象技术点讲得更通俗~ 📀 ## Layered File System - File system organized into layers - Each layer in the design uses the features of lower layers to create new features  ## OS and File System - **One OS can support $\geq 1$ file systems** - **Many OS allow administrators or users to add file systems** - Each file system has its own format - disk file-system format - CD-ROM and DVD file-system formats - Unix supports: UFS (Unix File System), which is based on Fast File Systems - Linux supports over than 130 file systems - Extended File System (Standard Linux File System) - ext2, ext3, ext4 - Windows supports - Disk file formats - 16-bit File Allocation Table (FAT) - 32-bit File Allocation Table (FAT32) - New Technology File System (NTFS) - CD, DVD Blue-ray File System Formats ## File-System Implementation ### Requirements Structures used in file system implementation - Two categories of structures - **On-disk (on-storage) structures** contain information about - how to boot an OS stored in disk - the total number of blocks - the number and location of free blocks - the directory structure and individual files - **In-memory structures ** contain information used for - file-system management - Performance improvement via caching ### On-disk (on-storage) structures  要讲解 **磁盘存储结构(On-disk Structures)**,我们可以从「卷的物理布局」「核心数据结构」「不同文件系统的实现差异」三个维度展开,结合操作系统实例(如 Unix/Linux 的 UFS、Windows 的 NTFS)对比分析: #### 一、卷(Volume)的物理布局:从引导到数据的“四层结构” 一个磁盘卷(逻辑磁盘或分区)在物理上被划分为四个核心区域,如幻灯片底部示意图所示: ``` [引导块 (Boot Block)] → [超级块/卷控制块 (Superblock)] → [目录与文件控制块 (Directory & FCBs)] → [文件数据块 (File Data Blocks)] ``` ##### 1. 引导块(Boot Block) - **位置**:卷的**第一个块**(固定位置)。 - **作用**: - 存储**引导程序(Bootloader)**,用于启动操作系统(如 Windows 的 NTLDR、Linux 的 GRUB)。 - 若卷不包含操作系统,引导块为空或保留。 - **不同系统术语**: - Unix/Linux(UFS):称为 **引导块(Boot Block)**; - Windows(NTFS):称为 **分区引导扇区(Partition Boot Sector)**。 ##### 2. 超级块/卷控制块(Superblock/Volume Control Block) - **位置**:紧接引导块之后。 - **作用**:存储**卷的全局元数据**,是文件系统的“户口本”: - 卷的总块数、块大小(如 4KB); - 空闲块数量及指针(记录哪些块未被使用,用于分配新文件); - 空闲文件控制块(FCB)数量及指针(记录哪些 FCB 可用于创建新文件)。 - **不同系统术语**: - Unix/Linux(Ext 系列):称为 **超级块(Superblock)**; - Windows(NTFS):称为 **主文件表(Master File Table, MFT)**——本质是结构化的元数据数据库,而非简单块。 ##### 3. 目录与文件控制块(Directory & FCBs) - **位置**:超级块之后,存储文件系统的“索引”信息。 - **核心作用**: - **目录结构**:记录文件名与文件控制块的映射关系(如“`readme.txt` → inode 123”); - **文件控制块(FCB)**:每个文件对应一个 FCB,存储文件的元数据(权限、大小、创建时间、数据块位置等)。 - **不同系统实现**: - **Unix/Linux(UFS)**: - 目录项仅存储**文件名**和对应的 **inode 号**; - inode(索引节点)是独立的 FCB,包含文件元数据及数据块指针(如 12 个直接块、1 个间接块等)。 - **Windows(NTFS)**: - 所有目录项和 FCB 统一存储在 **主文件表(MFT)** 中,采用类似关系数据库的行记录结构; - MFT 不仅记录文件名、权限等,还直接存储小文件的内容(称为“常驻属性”)。 ##### 4. 文件数据块(File Data Blocks) - **位置**:卷的最后部分,存储文件的实际内容。 - **特点**: - 由 FCB 或 inode 中的“数据块指针”指向; - 大文件可能分散在多个不连续的数据块中(通过间接块或 MFT 指针链管理)。 #### 二、核心数据结构对比:Unix vs. Windows 的“元数据哲学” | **概念** | **Unix/Linux(UFS/Ext)** | **Windows(NTFS)** | | -------------- | ------------------------------------------------ | ------------------------------------------------- | | **卷控制块** | 超级块(Superblock):简单块结构,存储全局元数据 | 主文件表(MFT):结构化数据库,存储所有文件元数据 | | **文件元数据** | inode:独立于目录,通过 inode 号索引 | FCB:作为 MFT 的“行记录”,包含文件名和元数据 | | **目录项** | 仅存储文件名 + inode 号 | 存储文件名 + FCB 完整信息(MFT 中直接关联) | | **小文件优化** | 需访问 inode + 数据块 | MFT 直接存储小文件内容(减少磁盘寻道) | | **空闲块管理** | 超级块记录空闲块指针链 | MFT 中有专门记录空闲空间的“元文件”(如 $Bitmap) | **核心差异**: - Unix 采用**“分离式设计”**(目录存文件名,inode 存元数据),结构简洁,适合传统磁盘寻道优化; - NTFS 采用**“集成式数据库”**(MFT 统一管理所有信息),支持复杂元数据(如权限、加密、事务日志),适合现代高性能与可靠性需求。 #### 三、关键术语解析:从“为什么需要这些结构”理解设计逻辑 ##### 1. 为什么需要超级块/MFT? - **全局视角管理卷**:快速获取卷的总空间、空闲空间等信息,避免每次操作都遍历全卷; - **故障恢复基础**:记录空闲块状态,确保文件创建/删除时的元数据一致性(如 Ext4 的日志机制依赖超级块)。 ##### 2. 为什么目录不直接存文件数据? - **解耦合设计**:文件名可修改(如重命名),但文件元数据(如权限、数据块位置)不变,分离存储避免重复修改; - **高效查找**:目录仅需存储“短文件名+索引”,而非完整元数据,减少目录遍历开销(如 Unix 的 `ls` 命令快速列出文件名)。 ##### 3. 为什么 NTFS 的 MFT 能存小文件内容? - **减少 I/O 次数**:小文件(如几百字节)无需额外读取数据块,直接从 MFT 中读取,提升性能(如系统文件 `boot.ini` 通常直接存储在 MFT 中)。 #### 四、典型场景示例:文件创建的“幕后流程” 以在 Unix 系统创建文件 `test.txt` 为例,磁盘结构如何协作: 1. **引导块**:无操作(非引导卷); 2. **超级块**:查找空闲 inode 指针,分配一个空闲 inode(如 inode 500),更新空闲 inode 计数; 3. **目录结构**:在目标目录(如 `/home/user`)中添加一条记录 `test.txt → inode 500`; 4. **inode(FCB)**:在 inode 500 中记录文件权限(如 rw-r--r--)、大小(0 字节)、创建时间,数据块指针为空; 5. **数据块**:无操作(文件为空)。 **NTFS 流程类似但更集成**:在 MFT 中新增一行记录,直接包含文件名、权限、空数据(若文件小)或数据块指针(若文件大)。 #### 总结:磁盘结构的“管理金字塔” 从引导块(系统启动)→ 超级块/MFT(全局管理)→ 目录与 FCB(文件索引)→ 数据块(内容存储),磁盘结构形成了“从宏观到微观”的管理链条: - **底层硬件适配**:通过引导块实现系统启动,超级块/MFT 适配磁盘物理特性(块大小、寻道优化); - **上层功能支撑**:目录与 FCB 实现文件的“命名-寻址-权限”管理,数据块提供实际存储。 理解这些结构,就能明白操作系统如何在“0/1 物理磁盘”上构建出人类可理解的“文件与目录”世界~ 📊💾 ### In-Memory Structure 要讲解 **内存结构(In-Memory Structures)**,我们可以从「挂载管理」「目录加速」「文件打开状态的全局与进程级跟踪」三个维度拆解,结合**类比+场景示例**理解内存中如何高效管理文件系统运行时数据: #### 一、挂载表(Mount Table):记录“文件系统的内存地图” **包含:File-system mounts, mount points, file-system types** **核心作用** - 存储**当前系统中所有已挂载的文件系统信息**,相当于“挂载状态的实时台账”。 - 包含三大关键信息: 1. **挂载点(Mount Point)**:如 `/mnt/usb`(文件系统接入目录树的位置); 2. **文件系统类型 **:如 `ext4`、`NTFS`、`FAT32`(用于系统识别操作指令); 3. **设备标识**:如磁盘分区 `/dev/sdb1`、ISO 镜像路径(指向物理存储位置)。 类比场景 想象你有多个外接硬盘插在电脑上,挂载表就像**“外接设备管理器”**:记录每个硬盘插在哪个USB接口(挂载点)、硬盘的格式(文件系统类型)、硬盘的物理编号(设备标识)。系统需要访问文件时,先查挂载表找到对应的“位置地图”。 #### 二、目录结构缓存(Directory Structure Cache):加速“最近访问的目录查询” **Holds the directory information of recetly accessed directories** 核心作用 - 缓存**近期被访问过的目录元数据**(如目录下的文件名、子目录结构),避免频繁访问磁盘,提升文件检索速度。 - 典型场景: - 用户执行 `ls /usr/local` 后,该目录的结构会被存入缓存; - 后续再次访问 `/usr/local` 时,直接从内存读取目录内容,无需读取磁盘。 技术细节 - **缓存内容**:文件名与 inode/FCB 编号的映射关系(如 `bin → inode 1234`)、目录修改时间(用于缓存失效判断)。 - **淘汰策略**:采用 LRU(最近最少使用)算法,移除长时间未访问的目录条目,释放内存空间。 类比场景 类似**浏览器的网页缓存**:你第一次访问某个网页时,浏览器会下载完整内容并缓存;再次访问时,直接从缓存加载,速度更快。目录缓存就是操作系统的“文件路径浏览器缓存”。 #### 三、系统范围打开文件表(System Wide Open File Table):全局的“文件打开状态总账” 核心作用 - **面向所有进程**,记录**系统中所有已打开的文件信息**,是操作系统管理文件资源的“全局视角”。 - **For all processes, it contains a copy of the FCB of each file, tracking all open files and keeping the coutner of processes that have opened each file.** - 关键字段: 1. **FCB 副本**:存储文件元数据(如权限、大小、磁盘位置、创建时间),与磁盘上的 FCB/inode 同步; 2. **打开计数(引用计数)**:记录有多少个进程正在打开该文件(如计数为 3 表示 3 个进程打开了同一文件); 3. **文件状态**:是否只读、是否被锁定(用于并发访问控制)。 典型场景:多进程共享文件 假设进程 A 和进程 B 同时打开文件 `/etc/passwd`: 1. 系统表中创建一条记录,FCB 副本指向该文件的磁盘元数据,打开计数初始化为 1(进程 A 打开); 2. 进程 B 打开同一文件时,系统表找到已有记录,打开计数增至 2,无需重复读取磁盘元数据。 类比场景 类似**图书馆的“书籍借阅总台账”**: - 每本书(文件)对应一个条目,记录当前借阅人数(打开计数)、书籍位置(磁盘路径)、书籍状态(是否可外借/已损坏=文件权限); - 无论多少人借阅同一本书,总台账只记录一次书籍信息,避免重复登记。 #### 四、进程级打开文件表(Per Process Open File Table):进程的“私有文件访问记录” 核心作用 - **每个进程独立维护**,记录该进程当前打开的所有文件,是进程视角的“文件访问上下文”。 - 关键字段: 1. **指向系统表的指针**:关联到系统范围打开文件表中的对应条目(共享 FCB 元数据); 2. **文件读写指针**:记录该进程对文件的最后操作位置(如读取到第 100 字节,下次从 101 开始); 3. **访问权限**:进程对文件的权限(如只读、读写,可能因进程不同而不同)。 典型场景:同文件不同进程的独立操作 进程 A 和进程 B 同时读取文件 `data.txt`: - 系统表中共享 FCB(文件大小、磁盘位置等); - 进程 A 的读写指针在第 50 字节(刚读完前半部分),进程 B 的读写指针在第 0 字节(刚打开); - 两进程各自的操作互不干扰,系统通过进程表独立跟踪位置。 类比场景 类似**图书馆中多个读者的“个人借阅记录”**: - 总台账(系统表)记录书籍的全局信息(如编号、位置); - 每个读者的借阅卡(进程表)记录自己借的书、当前阅读进度(读写指针)、借阅权限(如是否可续借=访问权限)。 #### 五、四者协同工作:从“文件打开”到“读写操作”的流程 以进程打开文件 `/home/user/doc.txt` 为例,内存结构如何协作: 1. **挂载表查询**:确认 `/home` 所在的文件系统已挂载(如挂载点 `/home`,类型 `ext4`,设备 `/dev/sda5`); 2. **目录缓存查找**:检查 `/home/user` 目录是否在缓存中,若在则直接获取 `doc.txt` 的 inode 号,否则从磁盘读取并更新缓存; 3. **系统打开文件表操作**: - 若文件未打开,创建新条目:FCB 副本读取磁盘 inode,打开计数设为 1; - 若文件已打开,找到现有条目,打开计数+1; 4. **进程打开文件表操作**:创建条目,指向系统表中的对应条目,初始化读写指针为 0,记录进程权限(如用户 `user` 有读写权限); 5. **读写操作**:进程根据读写指针定位数据,系统表维护全局打开状态,目录缓存加速后续目录访问。 #### 总结:内存结构的“效率与隔离”设计目标 | 结构名称 | 核心目标 | 典型数据 | 跨进程共享性 | | -------------- | -------------------------- | --------------------------- | ------------ | | 挂载表 | 管理文件系统挂载状态 | 挂载点、文件系统类型 | 全局共享 | | 目录结构缓存 | 加速目录查询 | 文件名→inode 映射、修改时间 | 全局共享 | | 系统打开文件表 | 跟踪全局文件打开状态 | FCB 副本、打开计数 | 全局共享 | | 进程打开文件表 | 维护进程私有文件访问上下文 | 读写指针、访问权限 | 进程私有 | 通过这四层结构,操作系统实现了: - **效率优化**:缓存减少磁盘 I/O,共享表避免重复元数据存储; - **安全隔离**:进程级表确保各进程操作独立(如读写位置、权限隔离); - **资源管理**:全局表跟踪文件打开计数,避免文件被误删(需所有进程关闭后才允许删除)。 理解这些内存结构,就能明白操作系统如何在内存中“动态编织”文件系统的运行时状态~ 📚💻 ## File Open and Close ### Open File  - Search the **directory structure** on disk for the file and copy the content of entry(**metadata**)to **system-wide open file table** if the file is opened for the first time - Update the per-process open-file table by adding a pointer to system-wide open file table ### Close a file - Remove the file entry in system-wide open file table if no process to use it anymore - Update the per-process table by removing a pointer to system-wide open file table ## Virtual File Systems 一句话说人话,VFS = Java - VFS allows the same API to be used for different types of file systems - Separatesfile-system generic operations fromimplementation details - Implementation can be one of many file systems types, or network file system ## Directory Implementation - Linear list of file names with pointer to the data blocks - 说人话,搞个数组存 file name. - Hash Table - Linear list with hash data structure - 说人话,把线性表变成哈希当作 map 用 ## Allocation Methods ### Contiguous allocation - Each file occupies set of contiguous blocks - Each file can be located by start block # and length (total number of blocks) - *i.e.* A file that occupies $n$ blocks: $b, b+1, \cdots , b + n - 1$ - Advantage - Simple - Each to access - Minimal disk head movement - 磁盘按磁道(Track)和扇区(Sector)组织,连续块通常位于同一磁道或相邻磁道,**磁头移动距离最短**。 - Problems - Not suitable for a file with varied size: file size must be determined at the begenning (size-declaration) - 若预留空间过大,浪费磁盘;预留过小,文件无法写入。 - External Framgentation - 现象:随着文件频繁创建和删除,磁盘空闲块被分割为不连续的小块,导致: - 总空闲空间足够,但无法分配大文件(如空闲块总和为 100GB,但都是 <1GB 的碎片)。 - Solution: compacts all free space into one contiguous space - Compaction can be done off-line (down time) or on-line - Internal Fragmentation #### Example of Contiguous Allocation ##### 前提条件 - **逻辑地址(LA, Logical Address)**:文件内的字节偏移,从 `0` 开始计数。 - **块大小**:`512 字节`(每个磁盘块存储 512 字节数据)。 - **文件 `tr` 的元数据**: - 起始物理块号:`14`(即该文件存储在磁盘的第 14、15、16 块,共 3 个连续块)。 - 逻辑地址到物理地址的转换公式: $$ \text{物理地址} = (\text{Q} + \text{起始块号}) \times \text{块大小} + \text{R} $$ 其中: - **Q**:逻辑地址对应的**相对块号**(相对于文件起始块的偏移,从 0 开始)。 - **R**:逻辑地址在块内的**字节偏移量**($0 \leq R < 512$)。 问题:For tile tr, if a byte's LA is 1025, what is its physical address? **Step 1: 拆分逻辑地址为块号和偏移量** $$ \text{逻辑地址} \div \text{块大小} = \text{商(Q)} \quad \text{余(R)} $$ 代入: $$ 1025 \div 512 = 2 \quad \text{余} \quad 1 $$ - **Q = 2**:表示逻辑地址 `1025` 位于文件内的第 **3 个块**(相对块号从 0 开始,Q=0 是第 1 块,Q=1 是第 2 块,Q=2 是第 3 块)。 - **R = 1**:表示在块内的偏移量为 `1 字节`(即该地址是块内的第 2 个字节,因为偏移从 0 开始)。 **Step 2: 计算物理块号** 文件 `tr` 的起始物理块号为 `14`,相对块号 `Q=2` 对应的物理块号为: $$ \text{物理块号} = \text{起始块号} + \text{Q} = 14 + 2 = 16 $$ 即该逻辑地址对应磁盘的 **第 16 块**。 **Step 3: 计算物理地址** $$ \text{物理地址} = \text{物理块号} \times \text{块大小} + \text{R} = 16 \times 512 + 1 = 8192 + 1 = 8193 $$ **常见错误** 1. **相对块号 Q 从 0 开始**: - 不要误认为 Q 是“第几个块”(如 Q=2 是第 3 个块),而是相对于起始块的偏移量(起始块对应 Q=0)。 2. **块大小的作用**: - 块大小决定了逻辑地址拆分的粒度。若块大小为 4KB(4096 字节),则逻辑地址除以 4096 得到 Q 和 R。 3. **连续分配的地址唯一性**: - 由于文件存储连续,物理块号可通过“起始块 + Q”直接计算,无需查找链表或索引表,这是连续分配**访问高效**的核心原因。 #### Modified Contiguous Allocation  ### Linked Allocation - Each file is a linked list of blocks, ends at `NULL` pointer - Each block contains pointer to next block - Advantages - Solved the external-fragmentation problem and size-declaration problems of contiguous allocation - No need to find contiguous blocks - Disadvantage - Slow, you have to visit $O(n)$ elements #### Example 1 - Each file is a linked list of blocks, ends at `NULL` pointer - Blocks may be scattered anywhere on the disk - Physical address - $R$ byte in the $Q$ block in the list (index starts from $0$) - $Q$ block index in the list relative to the start - $R$ displacement into the block  **Step 1: 得到 data 部分的大小** $$ \text{data} = \text{block size} - \text{pointer} = 512 - 1 = 511 \text{ bytes} $$ - 逻辑地址需按**数据部分的大小**拆分,而非整个块的大小。 **Step 2: 逻辑地址拆分** $$ \text{逻辑地址} \div \text{数据部分大小} = \text{商(Q)} \quad \text{余(R)} $$ - **Q**:链表中的**块索引**(从 0 开始),表示逻辑地址属于第 $Q+1$ 个块。 - **R**:块内数据部分的**字节偏移**($0 \leq R < 511$)。 #### Example 2 ##### Linked allocation 的关键差别 | | 顺序 (contiguous) allocation | **链式 (linked) allocation** | | ----------------- | ---------------------------- | --------------------------------- | | 磁盘块在物理空间 | 必须相邻 | 可以散落在任何位置 | | 块号计算 | `start + Q` | **只能沿着指针逐块走** | | 访问第 *Q* 块耗时 | O(1) | O(Q)(最坏要走完前面 *Q* 个指针) | 在链式分配里,每个磁盘块的“下一块”信息就藏在指针字节里。文件的块可以像你的例子那样: ``` 9 → 16 → 1 → 10 → 25 ``` 完全不连续。 于是: - **逻辑地址 512** 告诉我们“落在第 1 块(从 0 数)”,但 - 第 1 块的 **物理块号** 并不是 `start (9) + 1 = 10`,而是链表里指针跳过去的 **16**。 如果你硬套 `(9 + Q)`: | Q | `(9 + Q)` 得到的“假块号” | 真实链表块号 | | ---- | ------------------------ | ------------ | | 0 | 9 | 9 | | 1 | 10 | **16** ⟵ 错 | | 2 | 11 | 1 ⟵ 再错 | 可见只要链表里出现一次“跨越”,这条简单算式就失效了。 ##### 关于块大小与块内偏移 - **块大小 (block_size)** 依旧是 512 Bytes——这是磁盘对块寻址的粒度。 - 指针 1 Byte 只是占用了块最后 1 Byte 的**存储空间**,它不会改变“物理块大小”。 因此块内有效数据区只有 511 Bytes,但物理块地址仍按 512 Bytes 对齐。 **所以我们的步骤是:** 1. **`Q = ⌊Logical / 511⌋`,`R = Logical mod 511`** 2. **沿链表走 Q 步 找到真正的物理块号** 3. **物理地址二元组 = (物理块号, R)** **在你的例子里得到 (16, 1)。这就是为什么不能直接用 `(Q + 起始块号)` 来推算物理块号。** ### Linked Allocation Variation: File Allocation Table - An important variation on linked allocation used in MS-DOS - Indexed in physical block no. - Each entry stores the no. of next block for this file - Like a linked list, but faster on disk and cacheable - Simple and efficient #### **1. 什么是FAT?** **文件分配表(File Allocation Table, FAT)** 是微软DOS系统中使用的一种磁盘空间分配方法,属于**链式分配的改进版本**。它通过一个集中的表格记录文件块的链接关系,而非在每个数据块中存储指针,从而提升了访问效率和空间利用率。 #### **2. FAT的核心特点** ##### (1)**基于物理块号的索引** - **索引方式**:FAT表以**物理块号**为索引(下标),每个条目对应一个物理块的“下一块地址”。 - 例如:物理块号为217的条目,记录该块的下一个块号(如618)。 - **表格结构**:FAT表存储在磁盘固定位置(如引导扇区),开机时加载到内存,支持快速查询。 ##### (2)**集中存储块链接关系** - **传统链式分配**:每个数据块末尾需存储下一块的指针(如1字节),占用用户数据空间。 - **FAT模式**:**数据块中无需存储指针**,所有块的链接关系集中存储在FAT表中。 - 优势:每个数据块的全部空间(如512字节)均可用于存储用户数据,无额外开销。 ##### (3)**快速访问与缓存友好** - **无需磁盘寻道遍历**:传统链式分配需逐个块读取指针(多次磁盘I/O),而FAT表在内存中可直接查询,访问速度大幅提升。 - **缓存特性**:FAT表常驻内存(或缓存),后续访问无需重复读取磁盘,适合频繁访问的文件系统。 ##### (4)**简单高效的链式逻辑** - 本质上仍是链式结构(块间逻辑上串联),但通过集中式表格实现了**顺序访问高效性**与**元数据管理便捷性**的平衡。 #### **3. FAT的工作原理(示例解析)** 以幻灯片中的文件`test`为例: - **目录项**:记录文件的**起始块号217**。 - **FAT表结构**: | 物理块号 | FAT表条目(下一块号) | | -------- | ---------------------------------- | | 217 | 618(指向第二个块) | | 618 | 339(指向第三个块) | | 339 | -1(或特定结束标记,表示文件结束) | - **文件块链**:`217 → 618 → 339` - **访问流程**: 1. 从目录项获取起始块号217。 2. 查FAT表中217的条目,得到下一块618。 3. 查FAT表中618的条目,得到下一块339。 4. 查FAT表中339的条目,发现结束标记,遍历完成。 #### **4. FAT vs. 传统链式分配:核心区别** | **特性** | **传统链式分配** | **FAT(链式分配变体)** | | ---------------- | ------------------------------- | ------------------------------- | | **指针存储位置** | 每个数据块末尾(占用用户空间) | 集中存储在FAT表(不占用数据块) | | **访问效率** | 需逐块读取指针(多次磁盘I/O) | 内存中直接查询FAT表(快速) | | **随机访问支持** | 仅能顺序访问 | 可通过FAT表跳转(需遍历链条) | | **空间利用率** | 每个块需预留指针空间(如1字节) | 数据块全为用户数据,无开销 | | **元数据管理** | 分散在数据块中 | 集中在FAT表(易于维护和备份) | #### **5. FAT的优缺点** - **优点**: 1. **高效性**:内存中查询FAT表,减少磁盘I/O次数。 2. **空间利用率高**:数据块无指针开销。 3. **实现简单**:适合早期操作系统(如DOS)的硬件环境。 - **缺点**: 1. **FAT表占用内存**:磁盘容量越大,FAT表条目越多(如FAT32用32位表示块号)。 2. **随机访问受限**:仍需链式遍历,不适合大规模文件的随机读写(对比索引分配)。 #### **6. 为什么FAT比传统链式分配“更快”?** - **关键优化**: - **一次磁盘读取,多次内存查询**:FAT表只需首次加载到内存,后续访问直接查内存,无需每次访问块时读取指针(传统链式分配需每次读取块内指针,涉及磁盘寻道)。 - **缓存友好**:FAT表常驻内存或缓存,符合局部性原理,提升重复访问效率。 #### **总结:FAT的核心价值** FAT通过**集中式元数据管理**(FAT表)和**内存缓存技术**,在保持链式分配灵活性的同时,显著提升了访问速度和空间利用率。尽管其设计较简单,但在早期操作系统中(如DOS、早期Windows)被广泛采用,成为链式存储优化的经典案例。 ### Indexed Allocation #### **1. 什么是索引分配?** **索引分配**是一种将文件数据块的指针(物理地址)集中存储在**索引块(Index Block)**中的磁盘分配方法。每个文件拥有独立的索引块,其中每个条目对应一个数据块的物理地址。通过索引块,系统可以直接定位任意数据块,无需顺序遍历,从而支持高效的随机访问。 #### **2. 核心原理与结构** ##### (1)**索引块的作用** - **集中存储指针**:所有数据块的物理地址被存储在一个或多个索引块中,而非分散在数据块内部(如链式分配)。 - Bring all the pointers together into the index blocks - 例:若文件由3个数据块组成(块号12、45、78),其索引块包含3个条目,分别指向这3个块。 - **目录项关联索引块**:文件的目录项中仅存储**索引块的物理地址**,而非数据块地址。 - Each entry points to a block in a file - Each file has its own index block(s) of pointers to its data blocks ##### (2)**访问流程** 1. 从目录项获取索引块地址,读取索引块到内存。 2. 根据逻辑块号(如第n个数据块),直接查询索引块中第n个条目,获取对应数据块的物理地址。 3. 访问目标数据块。 **示例图示**: ``` 目录项: 文件名称: test 索引块地址: 999(假设索引块存于物理块999) 索引块(块999)内容: 条目1 → 数据块12 条目2 → 数据块45 条目3 → 数据块78 逻辑块号2 → 直接查索引块条目2,访问数据块45 ``` #### **3. 关键优势** ##### (1)**支持随机访问(Random Access)** - 无需像链式分配那样顺序遍历块链,可直接通过索引块定位任意数据块。 - **应用场景**:数据库文件、多媒体文件(需频繁跳转读取)。 ##### (2)**无外部碎片(No External Fragmentation)** - 数据块可离散分配在磁盘任意位置,只需索引块记录其地址。 - 解决了连续分配中“碎片导致空间无法利用”的问题(如连续分配需要大块连续空间,而索引分配允许零散空间被高效利用)。 ##### (3)**分配灵活** - 新增或删除数据块时,只需修改索引块条目,无需移动其他数据块(对比连续分配的“整块移动”)。 #### **4. 主要缺点** ##### (1)**索引块的空间开销** - **小文件效率低**:即使文件仅占1个数据块,仍需至少1个索引块,导致空间浪费。 - 例:块大小为4KB,指针占4字节,一个索引块可存储 $ \frac{4KB}{4B} = 1024 $ 个指针。若文件仅含1个数据块,索引块仍需4KB空间,总开销为8KB(数据块+索引块),利用率仅50%。 - **对比链式分配**:链式分配(如FAT)无需为每个文件单独分配索引块,全局FAT表共享空间,小文件开销更低。 ##### (2)**索引块可能成为性能瓶颈** - 访问大文件时,若索引块过大(需多个索引块),可能需要多次磁盘I/O读取索引块(可通过多级索引缓解,但增加复杂度)。 #### **5. 与链式分配(FAT)的对比** | **特性** | **索引分配** | **链式分配(FAT)** | | ------------ | ------------------------ | ----------------------------- | | **指针存储** | 每个文件独立索引块 | 全局FAT表 | | **访问方式** | 随机访问(直接查索引) | 顺序访问(遍历链条) | | **外部碎片** | 无 | 无(块可离散) | | **空间开销** | 索引块(小文件浪费显著) | FAT表(全局共享,小文件友好) | | **典型应用** | 大文件、随机访问场景 | 中小文件、顺序访问场景 | #### **6. 扩展:多级索引(Multi-Level Indexing)** - **问题**:当文件极大时,单级索引块可能无法容纳所有数据块指针(如块大小4KB,指针4字节,单索引块最多1024个指针,对应文件大小4MB)。 - **解决方案**: 1. **二级索引**:索引块中存储“次级索引块”的指针,次级索引块再存储数据块指针。 - 例:一级索引块指向1024个二级索引块,每个二级索引块指向1024个数据块,总数据块数为 $1024 \times 1024 = 1,048,576$,对应文件大小约4TB(4KB/块)。 2. **三级索引**:进一步扩展层级,支持更大文件(如EXT4文件系统的间接块机制)。 #### **7. 总结:索引分配的适用场景** - **优势场景**: - 需要频繁随机访问的大文件(如数据库、视频编辑文件)。 - 对空间碎片敏感的系统(如SSD,避免频繁擦除整块)。 - **劣势场景**: - 大量小文件(索引块开销占比过高)。 - 仅需顺序访问的场景(链式分配更高效)。 索引分配通过“空间换时间”的策略,在随机访问性能和碎片管理上优于传统分配方式,成为现代文件系统(如EXT2/3/4、NTFS)的核心技术之一。 #### Example ##### 索引分配示例解析 ###### **图示关键信息** - **文件jeep的索引块**:存储于物理块19。 - **索引块内容**(假设指针从索引0开始): | 索引位置 | 指针值(物理块号) | 含义 | | -------- | ------------------ | ------------------- | | 0 | 9 | 逻辑块0对应数据块9 | | 1 | 16 | 逻辑块1对应数据块16 | | 2 | 1 | 逻辑块2对应数据块1 | | 3 | 10 | 逻辑块3对应数据块10 | | 4 | 25 | 逻辑块4对应数据块25 | | 5~6 | -1(0xFF) | 空指针(无数据块) | - **假设条件**: - 指针大小:1字节(值范围:0~255,-1用0xFF表示)。 - 块大小:512字节。 ###### **问题1:LA = 513的物理地址计算** ##### 步骤1:解析逻辑地址(LA) $$ \text{逻辑块号} = \left\lfloor \frac{LA}{\text{块大小}} \right\rfloor = \left\lfloor \frac{513}{512} \right\rfloor = 1 $$ $$ \text{块内偏移量} = LA \mod \text{块大小} = 513 \mod 512 = 1 $$ ##### 步骤2:查询索引块获取物理块号 - 逻辑块号1对应索引块的**索引位置1**,指针值为**16**(即数据块16)。 ##### 步骤3:计算物理地址 - 物理块号16的起始地址:$16 \times 512 = 8192$ 字节。 - 块内偏移量1字节。 $$ \text{物理地址} = 16 \times 512 + 1 = 8193 $$ **答案1**:物理地址为 **8193**。 ###### **问题2:256KB文件需要的索引块数量** ##### 步骤1:计算数据块数量 $$ \text{文件大小} = 256\text{K} = 256 \times 1024 = 262144 \text{字节} $$ $$ \text{数据块数} = \frac{262144}{512} = 512 \text{个} $$ ##### 步骤2:计算单个索引块可容纳的指针数 $$ \text{单索引块指针数} = \frac{\text{块大小}}{\text{指针大小}} = \frac{512}{1} = 512 \text{个} $$ ##### 步骤3:判断索引块数量 - 512个数据块需要512个指针,恰好填满**1个索引块**(512指针/块)。 - 无需多级索引(单级索引足够)。 **答案2**:需要 **1个索引块**。 ##### **关键总结** 1. **索引分配的地址转换**: - 逻辑地址 → 逻辑块号 + 偏移量 → 索引块查询物理块号 → 物理地址 = 物理块起始地址 + 偏移量。 2. **索引块数量计算**: - 单级索引块数 = $\left\lceil \frac{\text{数据块数}}{\text{单块指针数}} \right\rceil$,本例中为1。 - 若数据块数超过单块指针数(如513个数据块),则需2个索引块。 ### Comparison | | Contiguous allocation | Linked allocation | Linked Allocation(FAT) | Indexed allocation | | -------------------------- | ------------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | | allocation | contiguous | scattered | scattered | scattered | | Directory hold information | For each file: file name, start block, number of blocks | For each file: file name, start block, end block. Linked through pointer | For each file: file name, start block<br>• One volume table indexed by block no. including next block no.<br> Linked through block no. | For each file: Index block no<br>• Index block: Pointers to data blocks | | Direct access support | Yes | No | Yes (Partial) | Yes | | fragmentation | External, internal | Internal | Internal | Internal | | Overhead | No | Pointer | FAT | Index block | | File size declaration | Necessary | Not necessary | Not necessary | Not necessary | ## Indexed Allocation – Schemes in Handling Large Files - One index block is not enough for large files - Three schemes to solve this issue - Linked scheme - Multilevel index - Combined scheme ## Free-Space Management - File system need to track available (free) blocks - Approaches - Bit vector (map) - Linked list - Groupiong - Counting ## Efficiency and Performance The efficient use of storage device space depends on: - Disk allocation method - **(Contiguous, Linked, and Indexed)** - Directory structure / algorithms - Types of data kept in file’s directory entry - Allocation of metadata structures - Fixed-size or varying-size data structures (e.g. the open file tables) **Ways to improve** efficiency and performance: - Keep data and metadata close together (for hard disk, but not SSD) - Use **buffer cache** for quick access - Use **asynchronous writes** (No need to write to disk immediately) - Use **Trim** mechanism (Keep the unused blocks for writing, No need to do garbage collection and erase steps before the device is nearly full) 最后修改:2025 年 09 月 02 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
